研究流程
因為違規資料嚴重右偏,為了避免造成預測偏差,本專案先將違規資料以分類模型分類成高風險及低風險違規餐廳,
再針對高風險 (即嚴重右偏的違規資料) 以回歸模型分別對輕度、中度、重度違規進行違規次數的預測。
* 準確率定義:若 (|預測值 - 實際值| <= 1) 視為預測正確,反之則視為預測失敗。*
* 最終準確率 = 預測為低風險的比例 * 分類準確率 + 預測為高風險的比例 * 迴歸準確率 * 分類準確率。*
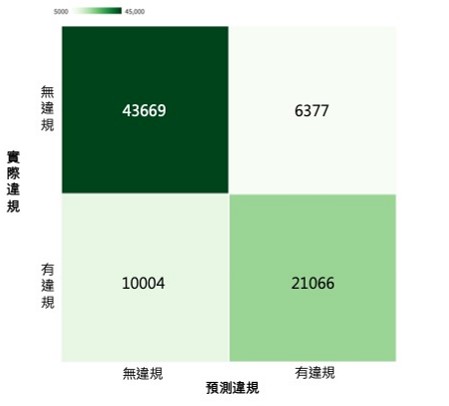
高/低風險違規資料分類結果 - 混淆矩陣
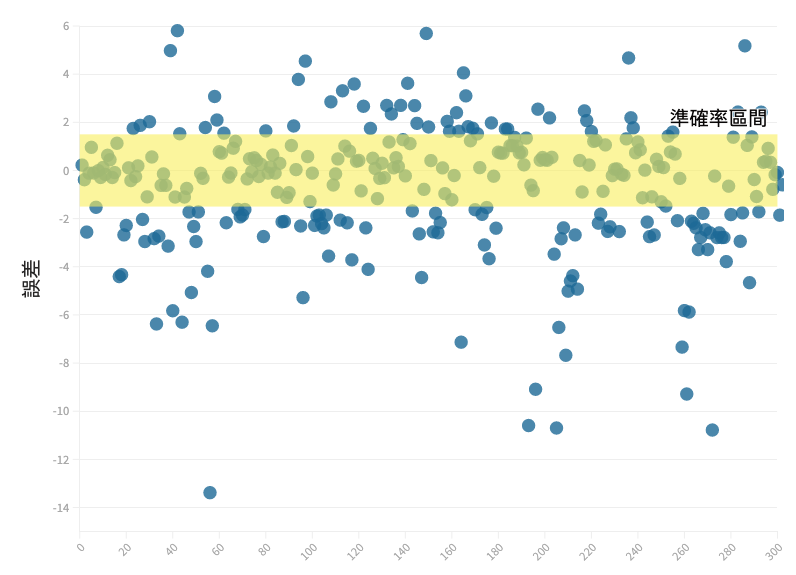
高風險違規資料誤差分佈
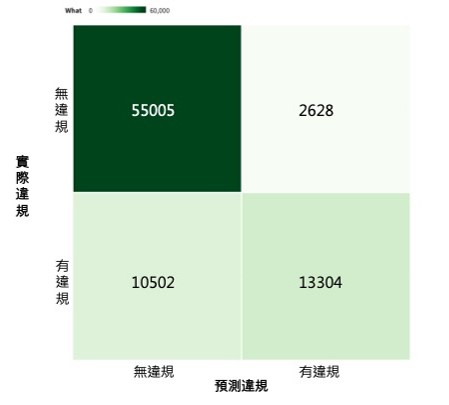
高/低風險違規資料分類結果 - 混淆矩陣
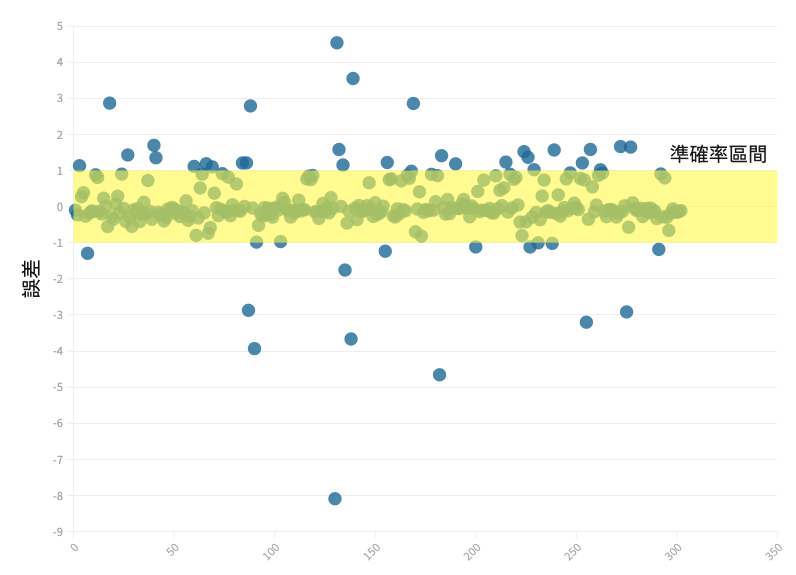
高風險違規資料誤差分佈
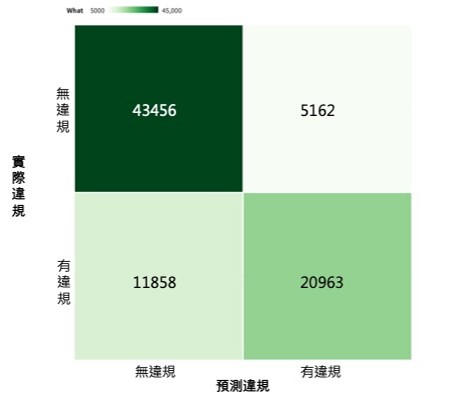
高/低風險違規資料分類結果 - 混淆矩陣
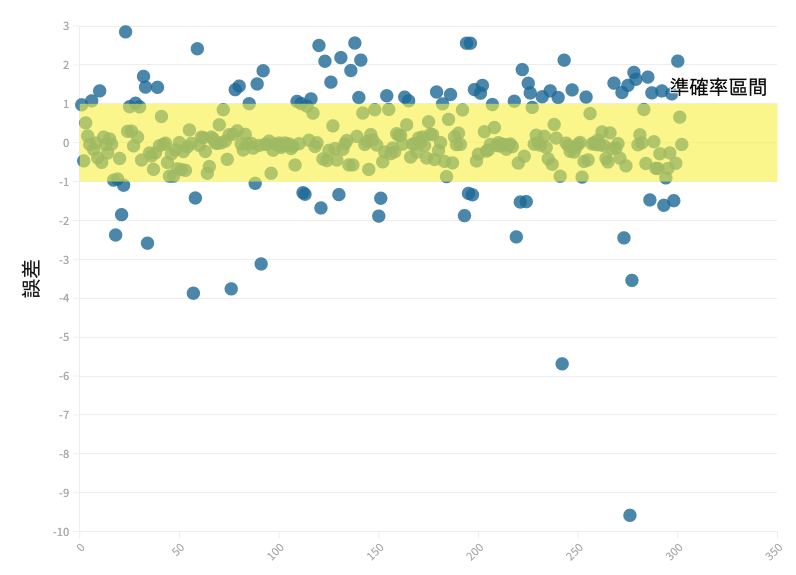
高風險違規資料誤差分佈
對餐廳的評論文字做TextBlob情感分析,掌握餐廳的基本輿情;
情感分析分數越低,違規程度越高。
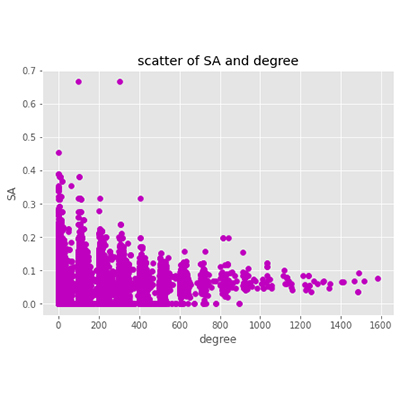
為了進一步捕捉更精確的食安關鍵字,我們以WIKI百萬文章為底的Word2Vector找出最有影響力的264詞袋,再透過模型挑出判別性TOP20的關鍵字。

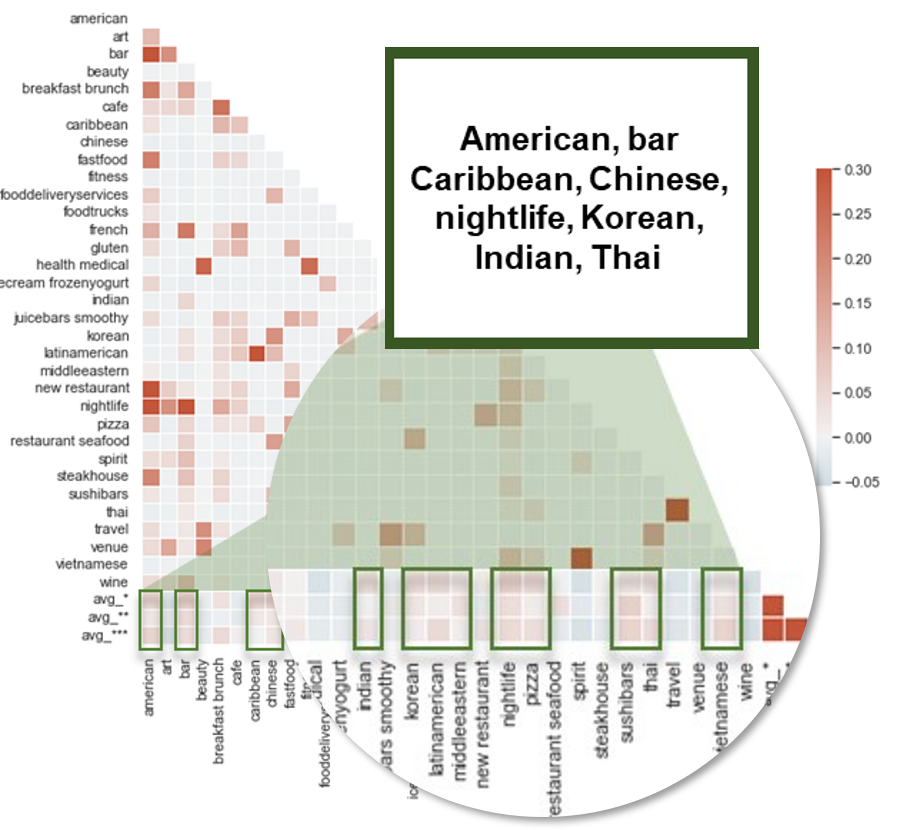
經過歸一化處理後,發現特定餐廳類型會明顯影響違規次數,例如:American, bar Caribbean, Chinese, nightlife, Korean, Indian, Thai。
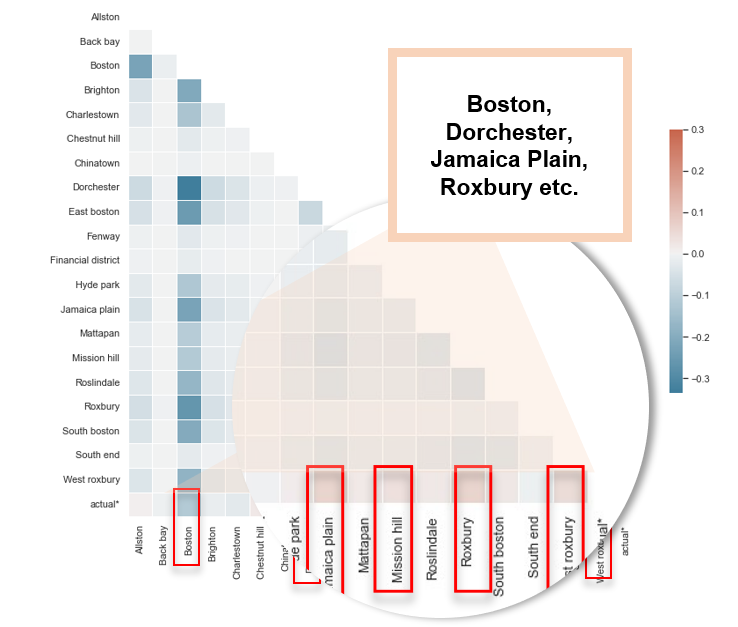
經過模型驗證後,發現特定城區如Boston, Dorchester, Jamaica Plain, Roxbury等會影響違規次數。
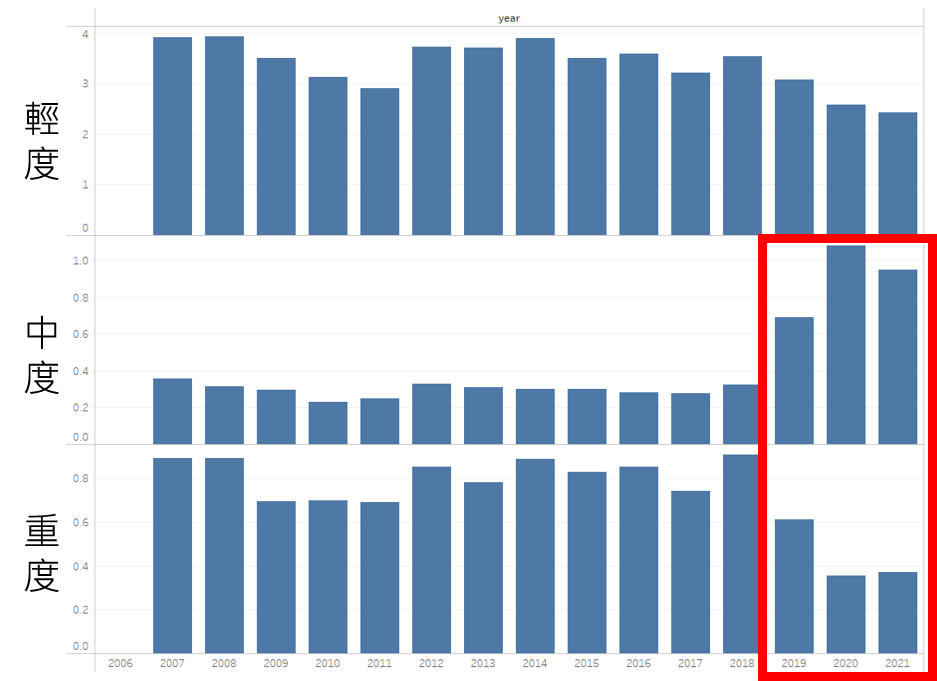
把稽查日期細分成年度來觀察,會發現2019年後的中度違規次數及重度違規次數和2019年前的相比有明顯落差。
© BDSE22 No.2版權所有